
Hoje a
necessidade de integrar diferentes fontes de dados é cada vez mais essencial.
Temos diversas fontes de dados espalhadas dentro de uma empresa. Podemos
encontrar dados em planilhas, em arquivos de texto e em diferentes bancos, como
SQL Server, Oracle, Access e etc.
Os dados
podem ter origem em departamentos diferentes, como Marketing, RH e Expedição. E
também pode ter origem em sistemas diferentes, como CRM (Customer Relationship
Management), ERP (Enterprise Resource Planning) e SCM (Supply Chain Management).
A
integração, transformação e padronização desses dados são essenciais para obter
informações mais assertivas possíveis para a tomada de decisão.
O SSIS (Sql
Server Integration Services) oferece recursos para facilitar essa integração de
dados, em especial o Data Flow Task (ou tarefa de fluxo de dados).
A imagem a
seguir ilustra um exemplo de integração de dados.

Figura 01 – Exemplo de integração de dados.
Utilizaremos
um exemplo prático para explicar o componente Data Flow. No nosso exemplo vamos
extrair uma tabela (qualquer uma) de um banco do SQL Server para um arquivo CSV
(Comma-separated value) que é
um arquivo de texto delimitado muito utilizado. Durante a extração
iremos incluir uma coluna extra no arquivo de saída.
Estou usando
como sistema operacional o Windows 8, como Banco de Dados utilizo o SQL Server 2014
express. Para desenvolver o pacote utilizo o SQL Server Data Tools 2013.
Obervação: Os conceitos aplicados aqui
podem ser utilizados nas edições anteriores.
O Data Flow
é uma “task” (ou tarefa) e pertence ao Control Flow (ou fluxo de controle).
Porem, costumo dizer que é uma “task” especial que possui uma aba própria. Você
escolhe o componente na aba Control Flow, mas o configura na aba Data Flow.
Vale lembrar
que os componentes da toolBox da aba control flow são diferentes dos
componentes da aba data flow. No control flow encontramos as “tasks”. No data
flow teremos Source, Transforms e Destinations.
A imagem a
seguir aponta algumas das diferenças entre as abas Control Flow e Data Flow.

Figura 02 – Diferenças entre as abas Control Flow e Data
Flow.
Source (Origem):
São
relacionados aos arquivos ou base de origem dos dados que serão carregados. De
onde os dados são extraídos.
Você pode se
conectar a base de dados utilizando as Origens “Oledb”,” Ado Net” e “ODBC”.
Pode se
conectar a planilhas do Excel, se conectar a Flat Files (Arquivos de texto:
txt, csv e etc) e se conectar até a arquivos XML.
Todo Data
Flow deve ter obrigatoriamente pelo menos uma origem. E essa origem deve ter
uma conexão.
No nosso
exemplo iremos utilizar o componente “Oledb Source” para nos conectarmos ao
Banco de Dados SQL Server.
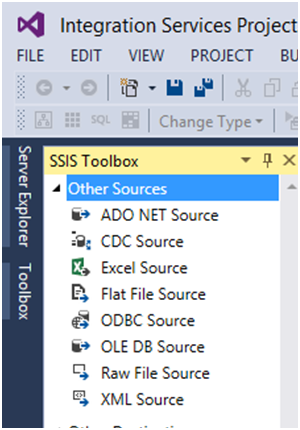
Figura 03 – As Origens (Source) disponíveis no SSIS.
Para
escolher a origem pode optar em dar um duplo clique ou clicar e arrastar para a
área de edição. O componente irá apresentar um erro (que é normal) devido à
falta de uma conexão.

Figura 04 – Componente Oledb Source com erro de conexão
Para
configurar a conexão podemos dar um duplo clique na origem ou clicar com o
botão direito e escolher Edit. Será aberta a janela de edição.

Figura 05 – Janela de edição do Ole DB Source
Como podemos
observar o campo “OLE DB connection manager” está em branco. Vamos criar uma
nova conexão clicando no botão New. Será aberta a janela de configuração.

Figura 06 – Janela de configuração do gerenciador de conexão
Em “Data
connections” são apresentadas as conexões já existentes. Para criar uma nova
clicamos no botão New novamente. Será
aberta a janela de Gerenciador de conexão.

Figura 07 – Janela do Gerenciador de conexão
No campo
“Provider” verificamos todos os provedores de conexão disponíveis.

Figura 08 – Provedores OLE DB disponíveis.
Escolhemos o
provedor desejado e clicamos em ok. No nosso exemplo utilizaremos o “Microsoft
OLE DB Provider for SQL Server”.
No campo
“Server Name” podemos colocar o ip, o nome do servidor ou se for local
colocamos “ponto” (como no nosso exemplo).

Figura 09 – Conexão SQL Server local
No campo “Log
on to the Server” você escolhe o tipo de autenticação no servidor. No nosso
caso utilizaremos a opção “Windows Authentication”.
No campo
“Connect to a database” escolhemos o Banco de Dados que iremos utilizar. No
nosso caso “Blog”.
Observação:
Escolha o Banco que desejar.

Figura 10 – Escolhendo o Banco de Dados Blog
Para saber
se a conexão esta correta, clicamos no botão “Test Connection”. Se tudo estiver correto será exibida uma
mensagem de sucesso.

Figura 11 – Mensagem de sucesso de conexão
De ok nas
janelas abertas, irá retornar a janela de edição onde deve escolher a tabela
que irá utilizar no campo “Name of the table or the view”. No nosso caso a
tabela “Cliente”.
Observação:
Escolha a tabela que desejar.

Figura 12 – Escolhendo a tabela Cliente
Se quiser
visualizar alguns dados da tabela (200 registros no Maximo) pode clicar no
botão “Preview”.

Figura 13 – Janela de pré – visualização - Preview
Retornando a
janela de edição clique em “ok”. Verificamos que o erro do componente sumiu e
que na janela “Connection Manager” aparece uma conexão.

Figura 14 – Criada a conexão LocalHost.Blog
Outro modo
de criar uma nova conexão é clicar com o botão direito na área do “Connection
Manager”, escolher o tipo de conexão e seguir os procedimentos citados
anteriormente.

Figura 15 – Criando nova conexão com botão direito
Transforms (Transformações):
As
transformações executam ações nos dados de origem. Essas ações podem ser
limpeza, conversão de tipos dados, separar e mesclar dados, criar novas
colunas, agregação e etc.
As
transformações são realizadas nos dados de Origem.
A
transformação não é obrigatória no Data Flow.
A imagem a
seguir apresenta a Toolbox e as transformações, você pode verificar que existem
diversas, fornecendo assim um leque de opções para tratamento e modificação dos
dados.

Figura 16 – Transformações disponíveis no SSIS
Como
continuação do nosso exemplo, utilizaremos a transformação “Derived Column” em
um exemplo simples.

Figura 17 – Transformação Derived Column
O objetivo é
adicionar uma coluna chamada “UF” na tabela cliente, e o valor dessa coluna
será “SP”. Para abrir o editor utilizamos um duplo clique na transformação ou
com o botão direito seleciona “Edit”. Será aberta a janela de edição.

Figura 18 – Janela de edição da transformação Derived Column
Do lado
superior esquerdo podemos verificar as variáveis e colunas disponíveis para se
aplicar a transformação. Do lado superior direito verificamos uma lista de
funções e operadores disponíveis. Não utilizaremos nenhum desses recursos em
nosso exemplo, mas quanto mais descobrirem a utilização dos mesmos, mais
recursos terão dessa transformação.
Abaixo
encontramos uma tabela com alguns campos:
·
Derived Column Name: Será o nome do campo (ou
coluna). No nosso exemplo “UF”.
·
Derived Column: Aqui definimos se a coluna
derivada será nova, com a opção “add as new column”, ou se irá substituir uma
coluna existente com a opção “Replace ‘Nome da coluna’”. No nosso exemplo
escolhemos “add as new column”.
·
Expression: Aqui é definido o valor (ou
conteúdo) do campo. Nesse local que utilizamos funções ou variáveis. No nosso
caso, como é um exemplo simples, utilizaremos a string “SP”.
·
Data Type: O tipo de dados desse campo. Define se será um texto,
numérico, data e etc. No nosso caso “Unicode String”.
·
Lenght: Define o tamanho do campo e funciona em
conjunto com o campo Data Type.
Realizadas
essas configurações devemos clicar no botão ok.
Destinations (Destinos):
Destino é o
local onde o resultado final do fluxo de dados é gravado. Assim como a Origem,
o Destino pode ser uma base de dados, uma planilha Excel, um arquivo de texto
(flat file) e etc.
As
configurações do destino e da origem são muito semelhantes, escolhemos um
componente e configuramos a conexão para esse componente.
Pelo menos
um Destino é obrigatório dentro do Data Flow. E esse Destino deve ter uma
conexão. No destino teremos os dados finais, já transformados e tratados. Isso
quando temos alguma transformação.
Para o nosso
exemplo utilizaremos o “Flat File Destination”
para que os dados sejam gravados em um arquivo “CSV”.

Figura 19 – Destino Flat File
Para abrir o
editor podemos utilizar um duplo clique no componente ou botão direito opção
“Edit”.

Figura 20 – Janela de edição do destino Flat File
Para criar
uma nova conexão clicamos no botão “New”. Será aberta a janela de Formatos.

Figura 21 – Janela Flat File Format
No nosso
caso escolheremos “Delimited” e clicamos no botão “Ok”. Será aberta uma nova
janela, a de Edição do Gerenciador de Conexão.

Figura 22 – Janela Flat File Connection Manager Editor com
itens desabilitados
Essa janela
possui quatro abas localizadas no lado esquerdo: General, Columns, Advanced e
Preview. Por default a primeira janela é General. No campo “Connection Manager
Name” colocamos o nome da conexão, no nosso exemplo renomeei para CSV.
No campo
“File name” se coloca o “path” ou caminho do arquivo que também pode ser
localizado pelo botão “Browse”, como faremos. Será aberta a janela Abrir no
estilo Windows Explorer.

Figura 23 – Janela Browser para localizar o arquivo
Devemos
navegar até a pasta desejada. No canto inferior direito encontrará os tipos de
arquivos (TXT e CSV). No nosso caso será CSV. Se o arquivo já existe é só
seleciona-lo. Caso não exista colocamos o nome no campo “Nome”, no nosso caso o
nome do arquivo será “clientes”. Tudo pronto, clicamos no botão “Abrir”.
Retornaremos a aba General e podemos verificar que ela contém mais informações.
Observação: Escolha a pasta e o nome do
arquivo que desejar.

Figura 24 - Janela Flat File Connection Manager Editor com
itens habilitados
Em outra
oportunidade comentarei todos os campos, hoje só comentarei sobre o campo
“Column names in the first data row”. No nosso exemplo ficará marcado, pois
essa opção faz com que a primeira linha do arquivo “csv” seja o nome das
colunas. Após isso passamos para a aba Columns.

Figura 25 – Aba Columns
Na aba
Columns vamos citar o campo “Column delimiter”, onde mudaremos para “Semicolon”
que é o “ponto e virgula” (;). Esse delimitador irá separar as colunas no
arquivo de texto como veremos posteriormente. A próxima aba é a “Advanced”.

Figura 26 – Aba Advanced
Na aba “Advanced”,
podemos configurar campo por campo. Podemos mudar o tipo do campo em “Data
Type”, adicionar ou deletar um campo.

Figura 27 – Aba Preview
Na aba
“Preview” podemos pré visualizar os registros. Após tudo configurado devemos
clicar no botão “Ok”.

Figura 28 – Janela de edição com a conexão CSV
Retornando
ao Editor podemos verificar a conexão “CSV” já configurada no campo “Flat File
connection manager”. Nessa tela podemos citar o campo “Overwrite data in the
file”. Quando marcado ele funciona como um update. Ele zera os dados antigos e
atualiza o arquivo com os dados novos. Permanece sempre os dados mais atuais.
Quando não é marcado funciona como um insert. Guarda os dados anteriores e
insere os novos. Acumula os registros a cada execução. Deve-se atentar a esse
comportamento.

Figura 29 – A aba Mappings
Na aba “Mappings”,
verificamos e editamos as colunas de entrada para as colunas de saída. No nosso
caso o SSIS mapeou automaticamente, pois as colunas de entrada tem o mesmo nome
das colunas de saída. Quando isso não ocorre, devemos editar manualmente esse
mapeamento. Mapeamento configurado, clicamos no botão “ok”.

Figura 30 – Conexão CSV criada
No
gerenciador de conexões verificamos a nova conexão nomeada como “CSV”.
Concluímos todas as configurações, agora devemos executar a tarefa para gerar
nosso arquivo csv. Podemos executar a tarefa dentro da aba Data Flow clicando com
o botão direito e escolhendo a opção “Execute task” ou podemos voltar para aba
Control Flow e clicar com o botão direito em cima da tarefa Data Flow e escolher
“Execute task” conforme a imagem a seguir.

Figura 31 – Executando o Data Flow Task
Após a
execução verá uma imagem como a seguinte:

Figura 32 – Execução do Data Flow finalizada com sucesso
Verificando
o local do arquivo podemos verificar que o arquivo csv foi criado. Recomendo
abrir o arquivo com o bloco de notas para ver sua real estrutura. Geralmente é
uma extensão reconhecida pelo Excel. Para abrir com o bloco de notas selecione
o arquivo, clique com o botão direito, escolha “abrir com” e depois “bloco de
notas”. O arquivo tem a seguinte aparência:

Figura 33 – Arquivo CSV
Esse foi um
exemplo simples, apenas para entendimento.
Esse tipo de
extração, de um Banco de Dados para um arquivo de texto, é uma pratica comum
dentro das organizações.
As
possibilidades são muitas. Uma sugestão seria realizar o processo inverso.
Utilizar como Origem um arquivo CSV ou Txt e como Destino uma base SQL Server
ou um arquivo Excel.
Outra
sugestão é ir testando as transformações disponíveis.
Para aqueles
que querem saber mais sobre os itens recomendo as referencias no final do
artigo.
Obrigado e
até a próxima!
Referencias:
Data Flow:
Transformação
de coluna derivada:
Conexões no
SSIS:
Nenhum comentário:
Postar um comentário